You've heard of Alan Turing? Turing award? Turing test?
How about the Enigma machines and encryption/decryption?
What about the first computers?
What's the connection between these three?
Bletchley Park. It's a great place and historically very significant - but underfunded and in need of maintenance otherwise it'll be lost forever. Please help save Bletchley Park for future generations. Help support it by visiting - it's a great day out.
If you are an Agile coach - go to the Agile Coaches Gathering which is being held at Bletchley Park.
Copyright © 2009 Ivan Moore
Sunday, March 8, 2009
Friday, March 6, 2009
Bootable USB sticks for conference presentations
If you have a programming workshop or tutorial to present at a conference, where people bring their own laptops and you want to give the participants programming things to do, then one of the things that always seems to take more time than you expect (during the session) is setting up environments etc before being able to actually do any programming.
With Stuart Ervine, a colleague of mine who is running a session on GWT at SPA2009 (book now!), we have done some experimenting and now have a setup that I think works quite well - so I wanted to share it here in case it is helpful to others presenting similar sessions.
Having presented "Programming In The Small" (PITS) with Mike Hill at "Software Craftsmanship 2009" I can report that it worked quite well in practice (not perfect though - more on the glitches later).
Providing a complete environment:
Stuart and I wanted an identical environment / setup for all of the participants, so time wouldn't be wasted getting everything working on lots of different platforms. Even if you provide one click installers, participants may be understandably reluctant to install some software just for your session. They may even have things installed which conflict with whatever you want to give them. Therefore, we thought it would be better to provide a complete environment - OS and all.
We considered two approaches, providing a virtual image (e.g. VMWare or VirtualBox) with everything installed and configured, or using a bootable USB stick. I attended Lasse Koskela and Markus Hjort's excellent session "Reading Code Without Psychic Powers" where they provided bootable CDs which included the complete environment for several different languages. It worked very well - if rather slow to initially boot up. Having had that experience as a participant, Stuart and I decided to try bootable USB sticks.
Making a bootable USB stick:
First - download the latest Ubuntu (currently 8.10) - and burn it to a CD (good instructions available on the Ubuntu site). Boot your computer off the CD and be patient while Ubuntu starts (it's slow off a CD). These instructions are provided entirely at your risk.
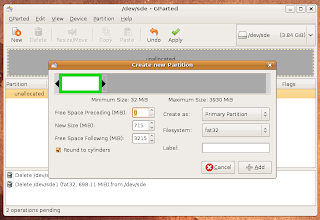
Create two partitions on the USB stick:
Write Ubuntu onto the USB stick:
You can copy whatever programs, files etc the participants need to the other partition (the second one you created). For the PITS session this meant Eclipse, Harmony JDK and an Eclipse workspace with the projects for the session. Running from the USB stick won't be very fast but may be acceptable.
To make your software run faster:
If you want the software to run faster, then set it up for participants to copy to the Ubuntu desktop (where it will be running from memory).
If you want to run memory hogging software from the desktop then participants might not have enough RAM (they might run out of memory and I think the live Ubuntu won't try to use the hard disk for swap space). You can set up Ubuntu to use swap space on the USB stick. To create and mount a 1Gb swap file:
Create an empty file the size of the swap space you want to provide (where /media/disk-1 is where the second partition created earlier is mounted) (this may take a few minutes):
dd if=/dev/zero of=/media/disk-1/swapfile.swp bs=1024 count=1024k
Provide an executable script in the second partition for participants to run if they need swap space, containing:
mkswap swapfile.swp
sudo swapon swapfile.swp
Mass production:
So far so good - however, you don't want to have to do this for every USB stick you need to create. Having created one USB stick which has everything set up just right, you can copy its entire contents (including partition table) to other USB sticks using the following (where /dev/sde is the "master" USB stick and /dev/sdf is the one you want to copy to):
dd if=/dev/sde of=/dev/sdf bs=8M count=250
This copies the first 2Gb from USB stick /dev/sde to USB stick /dev/sdf. In order to make this mass copying faster, for the PITS session we didn't use all the space of the USB sticks. We created the second partition using only part of the remaining space. The numbers for "bs" and "count" were arrived at experimentally to minimize the time it took to make the copies. (Multiply them together to work out the amount copied - i.e. using "bs=4M count=500" copies the same amount, but with my USB sticks was slightly slower). The copying may take a few minutes per stick.
Glitches and gotchas:
It would have been nice to allow participants to keep the USB sticks but they cost money and we're not working for some large consultancy who might want to do this for promotion.
You need one USB stick per machine (we had participants pairing).
We provided other mechanisms for participants to get the materials for the session - it was fairly straightforward for the PITS session as it was pure Java - so we provided the source (and Eclipse and IntelliJ project files) for participants who already have a Java environment. A lot of participants were very organized and had downloaded these materials from the conference web site before the session. We provided the materials in password protected zips and gave participants the password at the session.
And finally:
If you want to see this in action - go to Stuart's GWT session at SPA2009. Ubuntu rocks. GWT rocks. Stuart rocks. Mike rocks. SPA rocks.
Many thanks to Stuart Ervine for help with working this all out and writing it up. Many thanks to Mike Hill for preparing and co-presenting PITS.
Copyright © 2009 Ivan Moore
With Stuart Ervine, a colleague of mine who is running a session on GWT at SPA2009 (book now!), we have done some experimenting and now have a setup that I think works quite well - so I wanted to share it here in case it is helpful to others presenting similar sessions.
Having presented "Programming In The Small" (PITS) with Mike Hill at "Software Craftsmanship 2009" I can report that it worked quite well in practice (not perfect though - more on the glitches later).
Providing a complete environment:
Stuart and I wanted an identical environment / setup for all of the participants, so time wouldn't be wasted getting everything working on lots of different platforms. Even if you provide one click installers, participants may be understandably reluctant to install some software just for your session. They may even have things installed which conflict with whatever you want to give them. Therefore, we thought it would be better to provide a complete environment - OS and all.
We considered two approaches, providing a virtual image (e.g. VMWare or VirtualBox) with everything installed and configured, or using a bootable USB stick. I attended Lasse Koskela and Markus Hjort's excellent session "Reading Code Without Psychic Powers" where they provided bootable CDs which included the complete environment for several different languages. It worked very well - if rather slow to initially boot up. Having had that experience as a participant, Stuart and I decided to try bootable USB sticks.
Making a bootable USB stick:
First - download the latest Ubuntu (currently 8.10) - and burn it to a CD (good instructions available on the Ubuntu site). Boot your computer off the CD and be patient while Ubuntu starts (it's slow off a CD). These instructions are provided entirely at your risk.
Create two partitions on the USB stick:
- From the System menu, Administration submenu, select "Partition Editor"
- Take a note of the device(s) available.
- Insert a USB stick that you want to use for this (it will get completely overwritten, and must be at least 1Gb - we used 4Gb sticks).
- Right click on the USB stick that has been recognised and "Unmount Volume".
- In the "Partition Editor" (GParted) select menu item GParted -> Refresh Devices
- In the "Partition Editor" (GParted) select the USB stick from the menu GParted -> Devices
- if you proceed from this point with the wrong device selected then you'll trash your machine, so don't get it wrong. Clues about which device is the USB stick are the size of the device and that it wasn't on the list before you plugged it in.
- For each of the partitions on the USB stick (there will usually only be one) right click and "Delete"
- Click on the (now grey) bar which represents the partitions on the USB stick
- Click "New"
- Drag the right hand side of the bar and create a FAT32 partition large enough for the Ubuntu image (about 710Mb should be enough). See image below.
- Click on the (now grey) bar which represents the unpartitioned space on the USB stick
- Click "New"
- Create another partition - can be FAT32 or ext2 - doesn't really matter much. (I found FAT32 to be fine).
- Click "Apply"
- Close the "Partition Editor" (GParted)

Write Ubuntu onto the USB stick:
- From the System menu, Administration submenu, select "Create a USB startup disk"
- Select the device which is the USB stick (as noted above when creating the partitions). If you don't see your device in the list of "USB Disk to use", you might possibly have to unmount the newly created partitions of the USB stick, remove your USB stick and put it back in.
- Click "Make Startup Disk"
- Get a cup of tea - this'll take a few minutes
You can copy whatever programs, files etc the participants need to the other partition (the second one you created). For the PITS session this meant Eclipse, Harmony JDK and an Eclipse workspace with the projects for the session. Running from the USB stick won't be very fast but may be acceptable.
To make your software run faster:
If you want the software to run faster, then set it up for participants to copy to the Ubuntu desktop (where it will be running from memory).
If you want to run memory hogging software from the desktop then participants might not have enough RAM (they might run out of memory and I think the live Ubuntu won't try to use the hard disk for swap space). You can set up Ubuntu to use swap space on the USB stick. To create and mount a 1Gb swap file:
Create an empty file the size of the swap space you want to provide (where /media/disk-1 is where the second partition created earlier is mounted) (this may take a few minutes):
dd if=/dev/zero of=/media/disk-1/swapfile.swp bs=1024 count=1024k
Provide an executable script in the second partition for participants to run if they need swap space, containing:
mkswap swapfile.swp
sudo swapon swapfile.swp
Mass production:
So far so good - however, you don't want to have to do this for every USB stick you need to create. Having created one USB stick which has everything set up just right, you can copy its entire contents (including partition table) to other USB sticks using the following (where /dev/sde is the "master" USB stick and /dev/sdf is the one you want to copy to):
dd if=/dev/sde of=/dev/sdf bs=8M count=250
This copies the first 2Gb from USB stick /dev/sde to USB stick /dev/sdf. In order to make this mass copying faster, for the PITS session we didn't use all the space of the USB sticks. We created the second partition using only part of the remaining space. The numbers for "bs" and "count" were arrived at experimentally to minimize the time it took to make the copies. (Multiply them together to work out the amount copied - i.e. using "bs=4M count=500" copies the same amount, but with my USB sticks was slightly slower). The copying may take a few minutes per stick.
Glitches and gotchas:
- Be really careful about mount points (e.g. "/dev/sde") so as not to trash your hard disk.
- Not all machines will boot off a USB. The big glitch is that Apple Macs don't seem to like booting from a USB stick (and even some regular PCs don't). One potential solution for such participants is to provide a bootable Ubuntu live CD and use the USB stick for the programs to run in the live Ubuntu.
- Not all participants were overjoyed at using Ubuntu.
- Participants already using Ubuntu couldn't just run the software included in the second partition because the paths were set up for the "live CD" user.
- Participants need to have some easy way to go from having booted off the USB stick to running the software for the session - we provided a "run.sh" file but in the rush of people getting their machines to boot off the USB (trying to find which key to press to change the boot device) not everyone heard the instructions (which we should have given before handing out the USB sticks).
- Some participants took a while to find the right key to press to boot off a USB device - a lot of machines print the message saying which key to press for such a short time it is difficult to read it. It may be an idea to suggest that participants figure this out before the session.
It would have been nice to allow participants to keep the USB sticks but they cost money and we're not working for some large consultancy who might want to do this for promotion.
You need one USB stick per machine (we had participants pairing).
We provided other mechanisms for participants to get the materials for the session - it was fairly straightforward for the PITS session as it was pure Java - so we provided the source (and Eclipse and IntelliJ project files) for participants who already have a Java environment. A lot of participants were very organized and had downloaded these materials from the conference web site before the session. We provided the materials in password protected zips and gave participants the password at the session.
And finally:
If you want to see this in action - go to Stuart's GWT session at SPA2009. Ubuntu rocks. GWT rocks. Stuart rocks. Mike rocks. SPA rocks.
Many thanks to Stuart Ervine for help with working this all out and writing it up. Many thanks to Mike Hill for preparing and co-presenting PITS.
Copyright © 2009 Ivan Moore
Saturday, February 14, 2009
Two styles
Even simple programs can be written many different ways. This article shows an example of two different styles for a very simple program - I hope the difference is instructive.
The code is shown in Java - but the two styles are applicable to any object-oriented programming language.
The problem to solve
The problem is a slightly reduced version of the parsing part of this robot blocks programming contest problem. To slightly reduce the problem I just use the first two commands and treat the input as a string rather than a file.
Therefore, the problem is to parse input that looks like this:
No validation is needed - the input will always be well formed - there are no tricks in the question - it is as it looks.
The input will be used to control a robot. You can come up with whatever api you want - you can treat it as if you will be implementing the robot at some point too.
Now your turn
Please have a go at implementing this in Java or a similar language - (parsing input like that shown) - allow a maximum of one hour. If you have any questions about the problem, take the answer as being whatever makes it simplest - there are no tricks to this.
What did you end up with?
I've seen a lot of solutions to this over the last year. That is because I've been doing a lot of interviewing for my client (using the best interview question) and have used this example many times.
What most people end up with
Here's a solution in the most popular style:
This is a decent representative of this style. I've chosen a shortish variation of the style to keep down the amount of code you have to wade through (although it could have been slightly shorter still if I'd parsed the command type using the enum). A popular variation is to have a Command interface and different implementations for MoveOverCommand and MoveOntoCommand. One thing that is quite nice about the problem is that there is scope in the solutions for showing different programming style and taste.
As far as the "two styles" that I'm talking about, the important feature is that the RobotParser has getters for the numberOfBlocks and the Commands, which are NoJos.
An alternative solution
Hardly anyone implements this alternative style:
and:
A variation of this would be to have a RobotFactory which creates a Robot for a given number of blocks, to prevent the possibility of command methods being called before "setNumberOfBlocks". I would expect the implementation to use a BufferedReader if it were reading from a file rather than a string input. As before, I've gone for a short variation of this style.
In this style, the important feature is that there are no getters, and no Command class or classes. You could possibly describe this solution as being an example of "tell don't ask".
And finally ...
Most of the solutions I have seen to the problem have been during interviews that I have conducted. During these interviews, most solutions are the first style and hardly any of the second style.
I don't know whether the popularity of the first style is skewed by it being an interview situation, by the demographics of the people I am interviewing or for some other reason. Most of the interviewees didn't use TDD but did write automated unit tests after the code. However, the majority of those using TDD still produced the first style.
What do you think? What would you do? Which style is "better"? Is that a valid question? If you come up with a different solution that you think is interesting then please put a comment with a link to your blog - please don't paste code in your comments or they will get too long and probably won't format well anyway.
I'm looking forward to seeing something completely different - regex anyone? I don't know - I'm sure there are other styles but the first one shown is, by far, the one I have seen most often when interviewing for Java developers. (And, of course, different languages could produce completely different styles).
And finally - does anyone have good names for these two styles (maybe "getter style" vs "doer style")?
Copyright © 2009 Ivan Moore
The code is shown in Java - but the two styles are applicable to any object-oriented programming language.
The problem to solve
The problem is a slightly reduced version of the parsing part of this robot blocks programming contest problem. To slightly reduce the problem I just use the first two commands and treat the input as a string rather than a file.
Therefore, the problem is to parse input that looks like this:
10 move 4 over 3 move 3 onto 5 quiti.e. the first line is the number of blocks (used to set up the robot), the last line is "quit" (that's just how the input is - has no effect on the robot) and the lines in between are commands (each line is one command, e.g. "move over" is a single command with two parameters, the source block and the destination block).
No validation is needed - the input will always be well formed - there are no tricks in the question - it is as it looks.
The input will be used to control a robot. You can come up with whatever api you want - you can treat it as if you will be implementing the robot at some point too.
Now your turn
Please have a go at implementing this in Java or a similar language - (parsing input like that shown) - allow a maximum of one hour. If you have any questions about the problem, take the answer as being whatever makes it simplest - there are no tricks to this.
What did you end up with?
I've seen a lot of solutions to this over the last year. That is because I've been doing a lot of interviewing for my client (using the best interview question) and have used this example many times.
What most people end up with
Here's a solution in the most popular style:
package com.oocode;
import static java.lang.Integer.parseInt;
import java.util.ArrayList;
import java.util.List;
import com.oocode.Command.Type;
public class RobotParser {
private final int numberOfBlocks;
private final List
and:package com.oocode;
public class Command {
private final int sourceBlock;
private final int destinationBlock;
private final Type type;
public Command(int sourceBlock,
int destinationBlock,
Type type) {
this.sourceBlock = sourceBlock;
this.destinationBlock = destinationBlock;
this.type = type;
}
public enum Type {
MOVE_OVER,
MOVE_ONTO
}
public int getSourceBlock(){
return sourceBlock;
}
public int getDestinationBlock(){
return destinationBlock;
}
public Type getType() {
return type;
}
}
This is a decent representative of this style. I've chosen a shortish variation of the style to keep down the amount of code you have to wade through (although it could have been slightly shorter still if I'd parsed the command type using the enum). A popular variation is to have a Command interface and different implementations for MoveOverCommand and MoveOntoCommand. One thing that is quite nice about the problem is that there is scope in the solutions for showing different programming style and taste.
As far as the "two styles" that I'm talking about, the important feature is that the RobotParser has getters for the numberOfBlocks and the Commands, which are NoJos.
An alternative solution
Hardly anyone implements this alternative style:
package com.oocode;
import static java.lang.Integer.parseInt;
public class RobotParser {
private final Robot robot;
public RobotParser(Robot robot) {
this.robot = robot;
}
public void parse(String input) {
String[] lines = input.split("\n");
int numberOfBlocks = parseInt(lines[0]);
robot.setNumberOfBlocks(numberOfBlocks);
for (int i = 1; i < lines.length - 1; i++) {
String line = lines[i];
String[] parts = line.split(" ");
int sourceBlock = parseInt(parts[1]);
int destinationBlock = parseInt(parts[3]);
if(parts[2].equals("over")) {
robot.moveOver(sourceBlock, destinationBlock);
} else {
robot.moveOnto(sourceBlock, destinationBlock);
}
}
}
}
and:
package com.oocode;
public interface Robot {
void moveOver(int sourceBlock, int destinationBlock);
void moveOnto(int sourceBlock, int destinationBlock);
void setNumberOfBlocks(int numberOfBlocks);
}
A variation of this would be to have a RobotFactory which creates a Robot for a given number of blocks, to prevent the possibility of command methods being called before "setNumberOfBlocks". I would expect the implementation to use a BufferedReader if it were reading from a file rather than a string input. As before, I've gone for a short variation of this style.
In this style, the important feature is that there are no getters, and no Command class or classes. You could possibly describe this solution as being an example of "tell don't ask".
And finally ...
Most of the solutions I have seen to the problem have been during interviews that I have conducted. During these interviews, most solutions are the first style and hardly any of the second style.
I don't know whether the popularity of the first style is skewed by it being an interview situation, by the demographics of the people I am interviewing or for some other reason. Most of the interviewees didn't use TDD but did write automated unit tests after the code. However, the majority of those using TDD still produced the first style.
What do you think? What would you do? Which style is "better"? Is that a valid question? If you come up with a different solution that you think is interesting then please put a comment with a link to your blog - please don't paste code in your comments or they will get too long and probably won't format well anyway.
I'm looking forward to seeing something completely different - regex anyone? I don't know - I'm sure there are other styles but the first one shown is, by far, the one I have seen most often when interviewing for Java developers. (And, of course, different languages could produce completely different styles).
And finally - does anyone have good names for these two styles (maybe "getter style" vs "doer style")?
Copyright © 2009 Ivan Moore
Saturday, January 24, 2009
Making fields and methods as private as possible - a postmodern Thatcher.
Fields and methods should be declared as private as possible. As I mentioned in an article on the subject "I thought of writing a tool to do this that I was going to call "Thatcher" - it would privatize as much as possible".
I only realized a few days ago that I've already written it (I really am quite dense), and in fact had written it several years before writing that article.
How do you tell if fields and methods can be made private?
I think the most popular ways for people to tell are:
If you are paranoid, how do you tell if fields and methods can be made private?
The only safe way to tell, for a field or method that you want to see if it can be private, is to make it private and then see if the application still works.
How to automate that?
If you have good test coverage, then "the application still works" is automated as "the build (including tests) passes" (e.g. the build that you use on your CI server).
Then you are left with the problem "how do I tell if "public" can be changed to "private" and the build (including tests) still passes?".
Now that sounds familiar to me - it's rather close to what Jester does.
Jester - a mutation testing tool
I wrote Jester as a mutation testing tool. As it says on the web site: "Jester makes some change to your code, runs your tests, and if the tests pass Jester displays a message saying what it changed." The idea is that if you can change your code and the tests still pass then the tests aren't covering the code (other possibilities are that it's a behaviour preserving change, or the code is redundant).
Jester as a postmodern Thatcher
Jester can be used to implement Thatcher by configuring it to mutate "public" to "private" and "protected" to "private" (package visibility is harder!). I think this could be described as a postmodern programming approach - (re)using some code to do something it wasn't designed for.
I hadn't thought of doing this until it occurred to me a few days ago (and now it seems so obvious) because I had imagined that Thatcher would use static analysis and hence be very different (that's my modernist thinking, it would have to use static analysis to be a fast and "proper" implementation and the fact that it wouldn't always be correct would be a fault of the imperfect world).
It might be that someone has proposed this before (in which case, sorry, I don't remember).
Limitations of Thatcher implemented using Jester
It should be noted that using Jester for implementing Thatcher only works if your build (including tests) has sufficient coverage that you are happy that if it passes then that means the application works.
Also note that using Jester for this could take a really long time. If your build takes an hour then it would take many machine days to privatize even a very small amount of code.
An example run of Thatcher implemented using Jester
Here's an example of using the latest version of Jester ("simple jester" also described here) as Thatcher. For this example, I'm using Checkstyle as the code base for which I want to make fields and methods as private as possible. I chose Checkstyle for this example because the build is very fast!
(To try this out for yourself, you will need Java installed with java, javac and ant on the path. These instructions are for Windows. Replace <wherever> as appropriate).
BUILD SUCCESSFUL
Total time: 33 seconds
(or whatever time)
17 mutations survived out of 19 changes. Score = 11
took 0 minutes
(or whatever time)
In order to check that the checkstyle build can be run from the jester directory (i.e. still in <wherever>simple-jester-1.1) (which makes it simpler for running Jester in this example)
BUILD SUCCESSFUL
Total time: 21 seconds
(or whatever time)
Now edit "mutations.cfg" (in <wherever>simple-jester-1.1) and replace contents with:
%public%private
%protected%private
That configures Jester to try mutating "public" to "private" and "protected" to "private". Unfortunately, Jester cannot currently be configured to not mutate literal numbers - so in order to avoid Jester making mutations to literal numbers you have to be a bit cunning.
Create a text file in folder "<wherever>simple-jester-1.1\\jester" called SimpleIntCodeMangler.java with contents:
package jester;
public class SimpleIntCodeMangler implements CodeMangler {
public SimpleIntCodeMangler(ClassSourceCodeChanger sourceCodeSystem) {
}
public boolean makeChangeToClass() throws SourceChangeException {
return false;
}
}
Then (in <wherever>simple-jester-1.1) execute "javac jester\SimpleIntCodeMangler.java".
If "." is on the classpath before simple-jester.jar then the new version of SimpleIntCodeMangler will replace the version in simple-jester.jar, so Jester won't do the literal number mutations.
Now to run Jester/Thatcher (just on the one class "Checker"), execute:
java jester.TestTester "ant.bat -f <wherever>checkstyle-src-5.0-beta01\build.xml run.tests" <wherever>checkstyle-src-5.0-beta01\src\checkstyle\com\puppycrawl\tools\checkstyle\Checker.java
(note that on windows it has to be "ant.bat" and not just "ant")
Now Jester will run for a while, and eventually you get:
4 mutations survived out of 24 changes. Score = 84
took 5 minutes
If you want a simple way to visualize the results, then run "python makeWebView.py" and have a look at "jester.html".
To get the code changed to make methods and fields private which can be made private, then run "python makeAllChangesFiles.py jesterReport.xml" and you get a version of Checker.java called Checker.jester (in the same folder, i.e. "<wherever>checkstyle-src-5.0-beta01\src\checkstyle\com\puppycrawl\tools\checkstyle\") which has all the privatizations where the tests still pass.
The results for Checker.java show that addFileSetCheck, setModuleFactory, setSeverity and setClassloader can be made private and the "ant run.tests" build still passes. Having had a look at the code - it might be that these methods need to be public for something not covered by the tests but are needed for the application to work (because the only tests are unit tests and not end-to-end tests; this is a limitation mentioned earlier).
And finally
If you like that (or even if you don't) then please donate to my 5 countries (300 miles) in 3 days bike ride to raise money for the National Autistic Society.
Copyright © 2009 Ivan Moore
I only realized a few days ago that I've already written it (I really am quite dense), and in fact had written it several years before writing that article.
How do you tell if fields and methods can be made private?
I think the most popular ways for people to tell are:
- look for all references to the field or method and see if any are outside the class it is declared in
- change "public" to "private" and see if it fails to compile (e.g. red Xs in eclipse)
If you are paranoid, how do you tell if fields and methods can be made private?
The only safe way to tell, for a field or method that you want to see if it can be private, is to make it private and then see if the application still works.
How to automate that?
If you have good test coverage, then "the application still works" is automated as "the build (including tests) passes" (e.g. the build that you use on your CI server).
Then you are left with the problem "how do I tell if "public" can be changed to "private" and the build (including tests) still passes?".
Now that sounds familiar to me - it's rather close to what Jester does.
Jester - a mutation testing tool
I wrote Jester as a mutation testing tool. As it says on the web site: "Jester makes some change to your code, runs your tests, and if the tests pass Jester displays a message saying what it changed." The idea is that if you can change your code and the tests still pass then the tests aren't covering the code (other possibilities are that it's a behaviour preserving change, or the code is redundant).
Jester as a postmodern Thatcher
Jester can be used to implement Thatcher by configuring it to mutate "public" to "private" and "protected" to "private" (package visibility is harder!). I think this could be described as a postmodern programming approach - (re)using some code to do something it wasn't designed for.
I hadn't thought of doing this until it occurred to me a few days ago (and now it seems so obvious) because I had imagined that Thatcher would use static analysis and hence be very different (that's my modernist thinking, it would have to use static analysis to be a fast and "proper" implementation and the fact that it wouldn't always be correct would be a fault of the imperfect world).
It might be that someone has proposed this before (in which case, sorry, I don't remember).
Limitations of Thatcher implemented using Jester
It should be noted that using Jester for implementing Thatcher only works if your build (including tests) has sufficient coverage that you are happy that if it passes then that means the application works.
Also note that using Jester for this could take a really long time. If your build takes an hour then it would take many machine days to privatize even a very small amount of code.
An example run of Thatcher implemented using Jester
Here's an example of using the latest version of Jester ("simple jester" also described here) as Thatcher. For this example, I'm using Checkstyle as the code base for which I want to make fields and methods as private as possible. I chose Checkstyle for this example because the build is very fast!
(To try this out for yourself, you will need Java installed with java, javac and ant on the path. These instructions are for Windows. Replace <wherever> as appropriate).
- download checkstyle
- unzip
- cd to <wherever>checkstyle-src-5.0-beta01
- in order to check that everything is OK so far, execute "ant run.tests"
BUILD SUCCESSFUL
Total time: 33 seconds
(or whatever time)
- download Jester (the simple-jester variety)
- unzip
- cd to <wherever>simple-jester-1.1
- for the step below to work, execute "setcp.bat"
- in order to check that everything is OK so far, execute "test.bat"
17 mutations survived out of 19 changes. Score = 11
took 0 minutes
(or whatever time)
In order to check that the checkstyle build can be run from the jester directory (i.e. still in <wherever>simple-jester-1.1) (which makes it simpler for running Jester in this example)
- ant -f <wherever>checkstyle-src-5.0-beta01\build.xml run.tests
BUILD SUCCESSFUL
Total time: 21 seconds
(or whatever time)
Now edit "mutations.cfg" (in <wherever>simple-jester-1.1) and replace contents with:
%public%private
%protected%private
That configures Jester to try mutating "public" to "private" and "protected" to "private". Unfortunately, Jester cannot currently be configured to not mutate literal numbers - so in order to avoid Jester making mutations to literal numbers you have to be a bit cunning.
Create a text file in folder "<wherever>simple-jester-1.1\\jester" called SimpleIntCodeMangler.java with contents:
package jester;
public class SimpleIntCodeMangler implements CodeMangler {
public SimpleIntCodeMangler(ClassSourceCodeChanger sourceCodeSystem) {
}
public boolean makeChangeToClass() throws SourceChangeException {
return false;
}
}
Then (in <wherever>simple-jester-1.1) execute "javac jester\SimpleIntCodeMangler.java".
If "." is on the classpath before simple-jester.jar then the new version of SimpleIntCodeMangler will replace the version in simple-jester.jar, so Jester won't do the literal number mutations.
Now to run Jester/Thatcher (just on the one class "Checker"), execute:
java jester.TestTester "ant.bat -f <wherever>checkstyle-src-5.0-beta01\build.xml run.tests" <wherever>checkstyle-src-5.0-beta01\src\checkstyle\com\puppycrawl\tools\checkstyle\Checker.java
(note that on windows it has to be "ant.bat" and not just "ant")
Now Jester will run for a while, and eventually you get:
4 mutations survived out of 24 changes. Score = 84
took 5 minutes
If you want a simple way to visualize the results, then run "python makeWebView.py" and have a look at "jester.html".
To get the code changed to make methods and fields private which can be made private, then run "python makeAllChangesFiles.py jesterReport.xml" and you get a version of Checker.java called Checker.jester (in the same folder, i.e. "<wherever>checkstyle-src-5.0-beta01\src\checkstyle\com\puppycrawl\tools\checkstyle\") which has all the privatizations where the tests still pass.
The results for Checker.java show that addFileSetCheck, setModuleFactory, setSeverity and setClassloader can be made private and the "ant run.tests" build still passes. Having had a look at the code - it might be that these methods need to be public for something not covered by the tests but are needed for the application to work (because the only tests are unit tests and not end-to-end tests; this is a limitation mentioned earlier).
And finally
If you like that (or even if you don't) then please donate to my 5 countries (300 miles) in 3 days bike ride to raise money for the National Autistic Society.
Copyright © 2009 Ivan Moore
Saturday, January 17, 2009
My favourite conference (SPA) is open for registrations. Book before 31 January to catch the early-bird discount rate.
I'm programme co-chair (with Mike Hill) and very happy with the programme we've been able to assemble.
Book now.
Copyright © 2009 Ivan Moore
I'm programme co-chair (with Mike Hill) and very happy with the programme we've been able to assemble.
Book now.
Copyright © 2009 Ivan Moore
Sunday, January 4, 2009
Charity Day
I am doing a charity bike ride in June to raise money for the National Autistic Society (NAS). One of my sons is autistic and the NAS have been very helpful. I did a London to Paris bike ride for NAS in 2007.
Please donate!
Time is money
For the 2007 bike ride I paid the costs myself so all money donated went to the NAS. For the 2009 bike ride I'd like to do something equivalent but slightly different. I'm offering a day of my time for a donation that more than covers the costs. (The alternative is that I pay using roughly a day of my usual billing - but I'd like a generous charity minded company to donate more than that).
That day could be:
If you aren't in the market for a day of my time then please make a donation of any amount you'd like!
Copyright © 2009 Ivan Moore
Please donate!
Time is money
For the 2007 bike ride I paid the costs myself so all money donated went to the NAS. For the 2009 bike ride I'd like to do something equivalent but slightly different. I'm offering a day of my time for a donation that more than covers the costs. (The alternative is that I pay using roughly a day of my usual billing - but I'd like a generous charity minded company to donate more than that).
That day could be:
- Refactoring and TDD Training
- continuous integration - e.g. installing an automated CI system (e.g. TeamCity, build-o-matic or whatever)
- Agile consulting (I've been doing "Agile" a long time - papers at XP2000, XP2001, XP2002, OOPSLA, TOOLS. Presentations at XPDay, SPA, ACCU etc)
- other stuff (dunno - email me and we can discuss)
- publicity - I'll write a short blog article - anything from just the name of the company and the donation up to an article about what I did for you (you can review/edit before publication)
- "small print" - I'm based in London, England. Anything outside of London might require you to pay expenses too.
- "more small print" - If I get multiple offers then I'll choose whichever I prefer.
If you aren't in the market for a day of my time then please make a donation of any amount you'd like!
Copyright © 2009 Ivan Moore
Sunday, December 14, 2008
Running builds for previous revisions
Can you run the build for a previous revision of your code? Can you do that fully automatically or do you need manual steps? Should you care?
It's good to have an automated build
As Martin Fowler says "... you should be able to walk up to the project with a virgin machine, do a checkout, and be able to fully build the system."
There are lots of benefits of having a fully automated build. It means all developers are building in the same way, reducing "it works on my machine" problems. It helps with productivity - you don't make mistakes doing the build and then have to do it again to get it right. There are other benefits too - but there are lots of other articles about this topic so I don't want to repeat them here.
Turning the dials up
What Martin Fowler doesn't say is "... do a checkout for any revision ..." (rather than just the most recent), but I think it is what you should aim to do.
Why "any revision"?
One reason you might need to run the build for any revision is in order to work out which commit broke the build in the case where you have multiple commits between builds and the build is broken. There are other reasons too - e.g. finding out what change introduced some bug that has been hiding undetected for a while (i.e. didn't cause the build to break but now you've found it and want to find out how to fix it or when/how it got introduced).
(As an aside - some CI servers can help reduce the occurrence of multiple commits between builds, but even if you are running a CI server which builds multiple revisions in parallel on multiple build agents, if the build farm isn't large enough for the number of commits and the speed of the build, then you will end up with multiple commits between builds. Or if you take the approach of having the CI server run the build before committing then you end up with a bottleneck delaying commits if you don't have enough agents.)
Can you run the build for a previous revision of your code?
If your system includes a database - how do you manage the database schema? In some teams, this is one of the dirty secrets - it's done by running some scripts manually as necessary - hence you can't run the build for a previous revision (or in some cases even the most recent revision) just by checking out the code (for that revision) and running the build.
Many teams use something like dbdeploy so changes to the database are made as delta scripts which make the necessary changes to the database in synch with code changes. Although this allows database migration forwards in time - how many teams implement the rollback scripts to allow the database to be reverted so that it is in synch with previous revisions of the code? Often you have to just rebuild the database from scratch in that case - and the build script might not do that automatically.
What if you use maven and have snapshot dependencies? How do you build the code the same as it was built an hour ago?
Why fully automate?
Any manual steps in something that you don't do frequently makes it likely that you'll find it difficult to do when you need to. Furthermore, manual steps to build previous revisions prevent you from taking advantage of all of the features of some CI servers (TeamCity, Pulse and build-o-matic all allow manually triggered building of a previous revision of the code. build-o-matic will automatically build previous revisions of your code in some circumstances, so if your build doesn't support running the build automatically for a previous revision then it won't always work as expected).
One of the logical conclusions - your development environment should be checked in
Being able to run the build for any revision of your code might require you to have more things in your source control system than you are used to. This can be controversial (even though it's mentioned in Martin Fowler's well read CI article). I like to have absolutely everything that the build depends on in the source control system - even when it isn't source.
For example, on a Java project, I like to have Java itself, Ant etc all checked in. If you change which version of Java you use (which you are more likely to do than you might think) then you want to ensure that everyone is using the same version and that you can build the project as it was in the past (if Java isn't checked in then how are you going to be sure what version it is or was)? This can be controversial (Martin Fowler mentions "Java development environment" as something that you might not check in but I disagree with him on this specific case) - but if you take the ability to check out and build the code at any point in time it to it's logical conclusion then you have to include everything you need to build it - machine set up and all. One of the advantages of taking things to this level is that it is trivial to set up a new development machine - you just check out everything and you are ready. This isn't always possible - particularly on Windows - but is a worthy aim and more achievable than you might think.
Copyright © 2008 Ivan Moore
It's good to have an automated build
As Martin Fowler says "... you should be able to walk up to the project with a virgin machine, do a checkout, and be able to fully build the system."
There are lots of benefits of having a fully automated build. It means all developers are building in the same way, reducing "it works on my machine" problems. It helps with productivity - you don't make mistakes doing the build and then have to do it again to get it right. There are other benefits too - but there are lots of other articles about this topic so I don't want to repeat them here.
Turning the dials up
What Martin Fowler doesn't say is "... do a checkout for any revision ..." (rather than just the most recent), but I think it is what you should aim to do.
Why "any revision"?
One reason you might need to run the build for any revision is in order to work out which commit broke the build in the case where you have multiple commits between builds and the build is broken. There are other reasons too - e.g. finding out what change introduced some bug that has been hiding undetected for a while (i.e. didn't cause the build to break but now you've found it and want to find out how to fix it or when/how it got introduced).
(As an aside - some CI servers can help reduce the occurrence of multiple commits between builds, but even if you are running a CI server which builds multiple revisions in parallel on multiple build agents, if the build farm isn't large enough for the number of commits and the speed of the build, then you will end up with multiple commits between builds. Or if you take the approach of having the CI server run the build before committing then you end up with a bottleneck delaying commits if you don't have enough agents.)
Can you run the build for a previous revision of your code?
If your system includes a database - how do you manage the database schema? In some teams, this is one of the dirty secrets - it's done by running some scripts manually as necessary - hence you can't run the build for a previous revision (or in some cases even the most recent revision) just by checking out the code (for that revision) and running the build.
Many teams use something like dbdeploy so changes to the database are made as delta scripts which make the necessary changes to the database in synch with code changes. Although this allows database migration forwards in time - how many teams implement the rollback scripts to allow the database to be reverted so that it is in synch with previous revisions of the code? Often you have to just rebuild the database from scratch in that case - and the build script might not do that automatically.
What if you use maven and have snapshot dependencies? How do you build the code the same as it was built an hour ago?
Why fully automate?
Any manual steps in something that you don't do frequently makes it likely that you'll find it difficult to do when you need to. Furthermore, manual steps to build previous revisions prevent you from taking advantage of all of the features of some CI servers (TeamCity, Pulse and build-o-matic all allow manually triggered building of a previous revision of the code. build-o-matic will automatically build previous revisions of your code in some circumstances, so if your build doesn't support running the build automatically for a previous revision then it won't always work as expected).
One of the logical conclusions - your development environment should be checked in
Being able to run the build for any revision of your code might require you to have more things in your source control system than you are used to. This can be controversial (even though it's mentioned in Martin Fowler's well read CI article). I like to have absolutely everything that the build depends on in the source control system - even when it isn't source.
For example, on a Java project, I like to have Java itself, Ant etc all checked in. If you change which version of Java you use (which you are more likely to do than you might think) then you want to ensure that everyone is using the same version and that you can build the project as it was in the past (if Java isn't checked in then how are you going to be sure what version it is or was)? This can be controversial (Martin Fowler mentions "Java development environment" as something that you might not check in but I disagree with him on this specific case) - but if you take the ability to check out and build the code at any point in time it to it's logical conclusion then you have to include everything you need to build it - machine set up and all. One of the advantages of taking things to this level is that it is trivial to set up a new development machine - you just check out everything and you are ready. This isn't always possible - particularly on Windows - but is a worthy aim and more achievable than you might think.
Copyright © 2008 Ivan Moore
Subscribe to:
Posts (Atom)